


「毎日、suumoを開いて物件情報を手作業でチェックするのが大変……」そんなお悩みを抱えていませんか?
営業の現場では、新着物件の確認や相場情報の整理が欠かせませんが、手作業では時間がかかるうえ、見落としのリスクもあります。
そんなときに活用したいのが“スクレイピング”による自動取得。本記事では、非エンジニアでも実践できる「suumoの物件情報を自動取得する方法3選」をご紹介します。
最後まで読めば、あなたの業務に最適な自動取得方法がきっと見つかります!
当ブログがオススメする
業務自動化サービスランキング
| 1位:ジドウカ | 2位:Yoom | 3位:UiPath | |
|---|---|---|---|
| LP |  |  |  |
| 全体評価 | ★★★★★ | ★★★★☆ | ★★☆☆☆ |
| URL | ジドウカ公式サイト | https://lp.yoom.fun/ | https://www.uipath.com/ja |
| 特徴 | ☑お客様自身で開発する必要がない自動化サービス。 ☑BPOのような感覚で自動化したい内容を依頼することが可能。 | ☑450種類以上のサービスとの連携が可能。 | ☑業務フローを視覚化し直感的に自動化が可能。 |
| 自動化技術の幅 | RPA/ Google Apps Script / VBA / 生成AI / ローコード・ノーコードツール | オリジナルサービス | RPA |
| ユーザーの開発負担 | ◎ お客様自身は 開発の必要なし | △ 自社で開発が必要 | △ 自社で開発が必要 |
| 自動化までのフロー | ◎ 自動化したい内容を 伝えて待つだけ。 | △ 自社で要件定義し 開発・運用 | △ 自社で要件定義し 開発・運用 |
| 費用 | ◎ 月額1万円〜 | ◎ 無料でスタート可能 | ☓ 52万5000円 |
| こんな方におすすめ | ・自動化したい内容が決まっている ・手離れよく自動化したい ・あまりコストをかけたくない | ・社内にエンジニアがいる ・自社でノウハウを貯めている ・開発・運用体制が整っている | ・RPAで自動化できるか業務が何か判断できる人材がいる企業 ・自社内にエンジニアがいる |
なお、業務効率化や工数削減を目指しているものの、どの業務から自動化すべきか、どのツールや手段が自社に合っているのかがあいまいな方は、「業務自動化プラン診断」をお試しください。
かかる時間は1分ほど。4つの質問に答えるだけで、あなたに最適な自動化対象業務や、推奨される自動化手段を診断してもらえます。
効率よく自社に適した業務効率化を知りたい方は、ぜひ一度お試しください。
\ 4つの質問に答えるだけ /
この記事で紹介するツールの比較まとめはこちら!
| ツール名 | 特徴 | こんな人におすすめ | 直感的な操作性 | 対応できるサイトの幅広さ | データ精度・安定性 | 保守・メンテナンス性 | コスパ |
| Octoparse | ノーコード操作、初心者向け、日本語対応 | 手軽に始めたい、まず試したい | ★★★★★ | ★★★☆☆ | ★★★☆☆ | ★★★☆☆ | ★★★★☆ |
| ScrapeStorm | AIによる自動認識機能、ノーコードで操作可能 | プログラミングに詳しくないがWebデータを集めたい方、頻繁に更新されるWeb情報を自動で取得したい人 | ★★★★☆ | ★★★★★ | ★★★★☆ | ★★★☆☆ | ★★★☆☆ |
| Python(requests+Beautifulsoup) | 自由度最強、完全カスタマイズ可 | 自社専用ツールを作りたい、エンジニアリソースがある | ★★☆☆☆ | ★★★★★ | ★★★★★ | ★★★☆☆ | ★★★★★ |
suumo物件情報を自動化した方が良い理由
suumoには全国の物件情報が網羅されており、競合調査や新着案件の収集に最適です。しかし、その情報量ゆえに手作業での収集は非常に非効率です。
よくある課題
- 確認漏れが起こる:毎日すべてのページを目視チェックするのは現実的ではありません。
- 作業に時間がかかる:物件名、賃料、間取りなどを手入力するのは手間がかかります。
- 分析に使いづらい:Excelやスプレッドシートで比較・分析したいが、そもそもデータが手元にない。
Octoparse(オクトパース)
| メリット | ノーコードで直感的に操作できるテンプレート機能がある日本語対応がある |
| デメリット | 複雑なサイトではエラーが出やすい 無料版には機能制限がある |
| こんな方におすすめ | スクレイピング初心者社内業務を効率化したい担当者 非エンジニアの方 |
| 評価(☆5段階) | 直感的な操作性:★★★★★ 対応できるサイトの幅広さ:★★★☆☆ データ精度・安定性:★★★☆☆ 保守・メンテナンス性:★★★☆☆ コストパフォーマンス:★★★★☆ |
実際に使ってみた感想
「こんなに簡単にできるんだ!」と驚きました。画面をクリックして指定するだけで、すぐにデータ収集が始められるのはとても直感的に使えます。
ただ、動的なサイトや変則的なレイアウトだと少し苦戦する場面もありました。
「まず一歩踏み出したい」「できるだけ簡単に自動化したい」という方にピッタリです。
サービスの概要・使い方・特徴を紹介
Octoparseは、Webサイト上の情報をプログラミング不要で収集できるスクレイピングツールです。
基本操作は対象データをクリックで選択して保存するだけなので、エンジニア経験がない人でも扱えます。
主な特徴は以下の通りです。
・ノーコードで作業できる
・一覧→詳細ページの遷移も自動対応
・クラウド上で実行可能(PCを閉じても動作)
・無料プランあり。月額数千円〜の有料版でより高速・高機能に。
具体的な設定手順
- Octoparseをインストールして起動する
Octoparse公式サイト(https://www.octoparse.jp/ )にアクセスし、「ダウンロード」ボタンをクリックしてパソコンにインストールします。
インストール後、Octoparseアカウントを作成し、ログインします。


- Octoparseのダッシュボード画面で「テンプレートタスク」をクリック。

- 「suumo」と入力し、「SUUMO 求人情報」をクリックします。
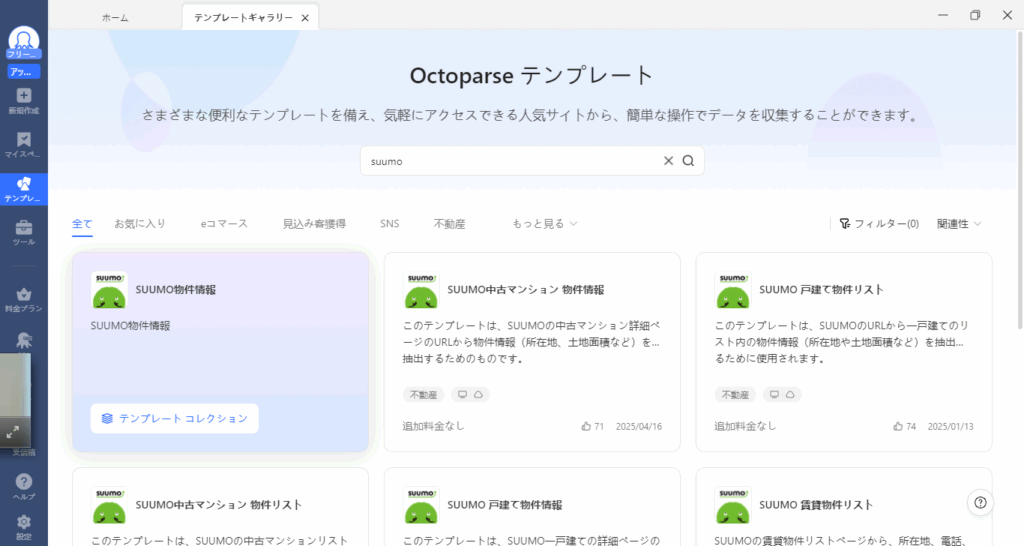
- 「URLを入力」に「https://suumo.jp/chintai/tokyo/city/」を入力し、「実行」をクリックします。
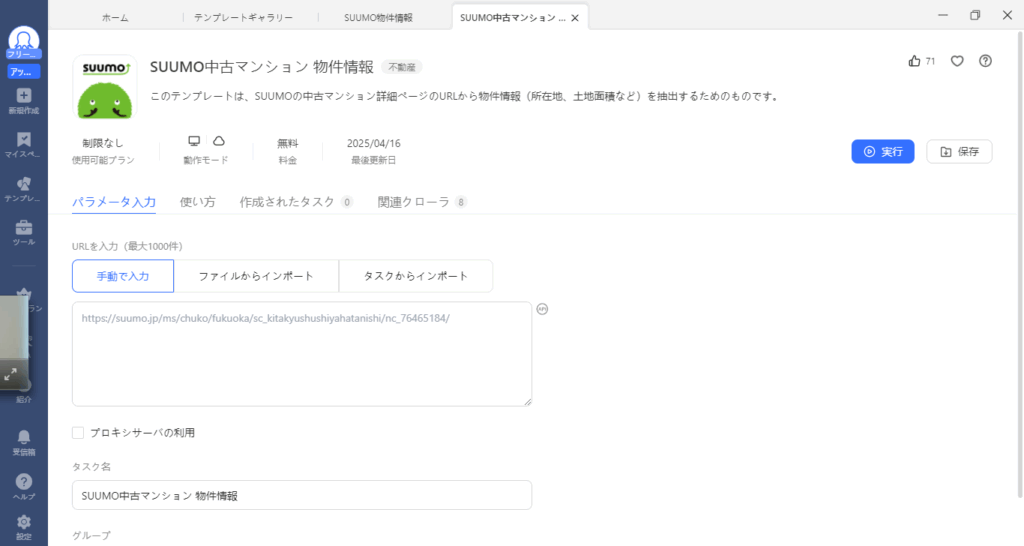
- 収集方法を設定する
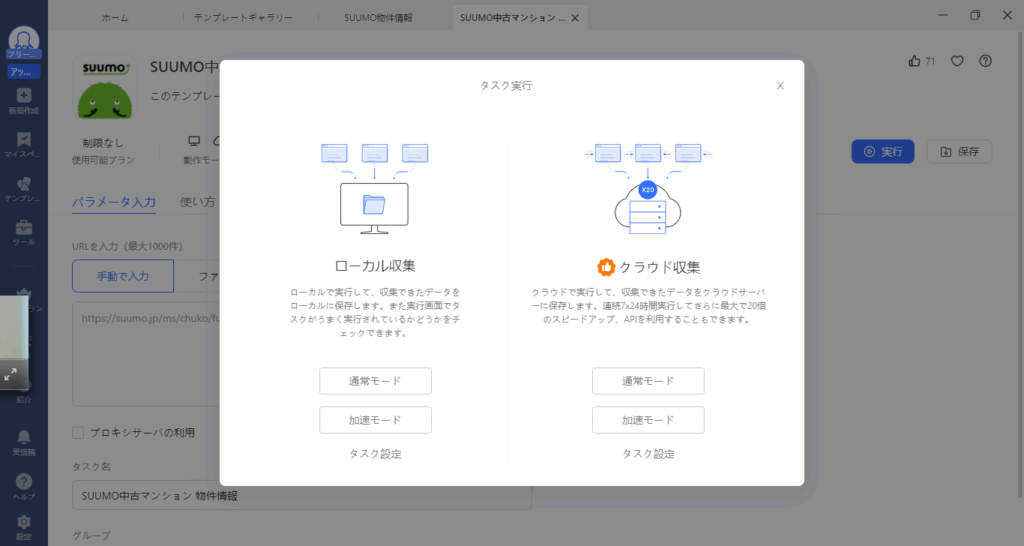
ローカル収集の「通常モード」をクリックします。
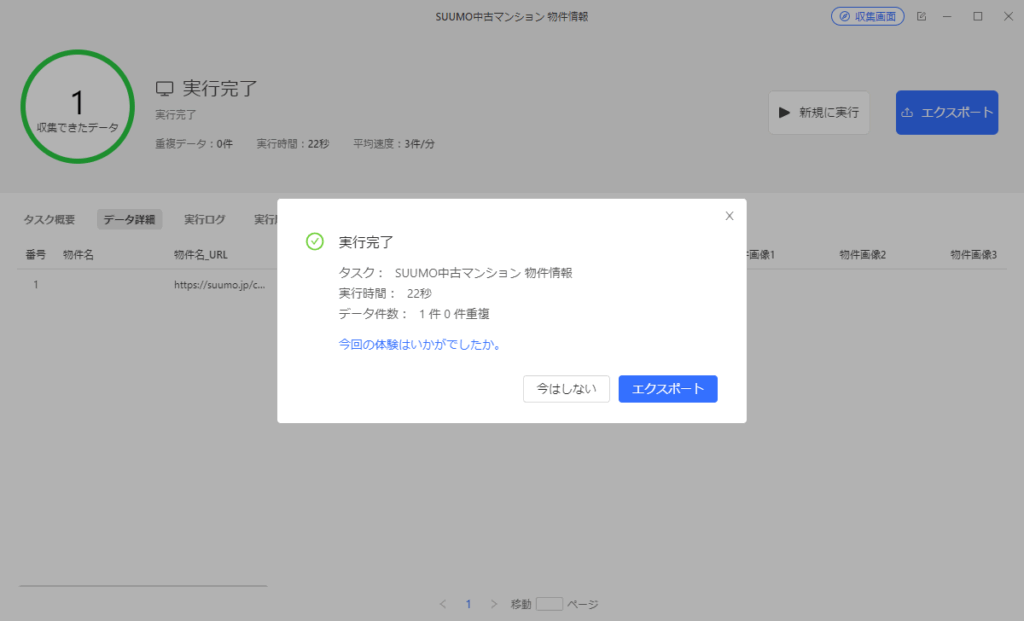
実行中の画面が表示されます。
- 「エクスポート」データをエクスポートする
ScrapeStorm
| メリット | ノーコードで使える AIによる自動データ認識 動的コンテンツや無限スクロールにも対応 |
| デメリット | 無料プランに制限がある 一部の複雑なサイトでは精度に課題あり 日本語のサポート情報が少ない |
| こんな方におすすめ | プログラミングに詳しくないがWebデータを集めたい方 頻繁に更新されるWeb情報を自動で取得したい人 |
| 評価(☆5段階) | 直感的な操作性:★★★☆☆ 対応できるサイトの幅広さ:★★★★★ データ精度・安定性:★★★★☆ 保守・メンテナンス性:★★★☆☆ コスパ:★★★☆☆ |
実際に使ってみた感想
特に便利だと感じたのは、プログラミングの知識が一切なくても操作できる点です。Webページを開いて、欲しいデータの部分をクリックするだけで、AIがその構造を認識し、自動でデータ抽出の候補を表示してくれます。この機能のおかげで、通常であれば煩雑なセレクタの指定などが不要になり、作業時間を大幅に短縮できました。
サービスの概要・使い方・特徴を紹介
ScrapeStormはニュース記事や求人情報、商品データ、企業情報など、インターネット上の構造化された情報を効率よく収集・整理するためのツールです。
特に、定期的に更新されるWebページや、大量のリストデータを管理したいユーザーにとって有用です。
具体的な設定手順(5ステップ)
- 公式サイトにアクセス
ScrapeStormの公式サイト(https://www.scrapestorm.com/)にアクセスしてインストーラーをダウンロード。インストーラーを実行。
- アカウントを作成する。
- 初回起動時にアカウントの登録またはログインが求められるので、メールアドレスなどを使って登録またはログインします。
- スクレイピングしたいWebサイトのURL(https://suumo.jp/chintai/tokyo/city/)を入力してGet Startedをクリックします。
- AIがページを自動解析し、抽出候補となるデータを表示します。必要に応じて手動でデータ項目を調整します。
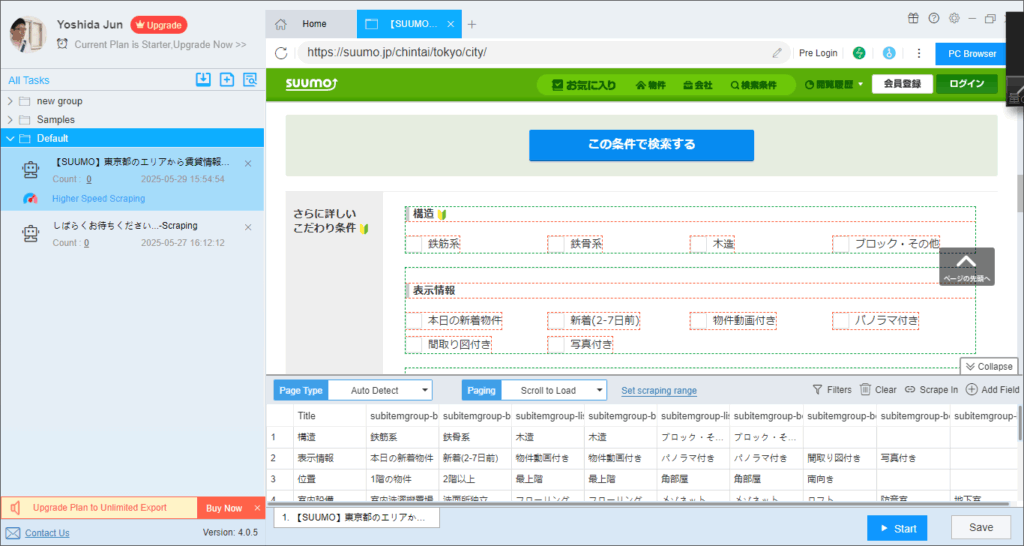
Python(requests+Beautifulsoup)
| メリット | 完全カスタマイズ可能、自由度が最も高い、動的データにも対応できる |
| デメリット | プログラミング知識が必要、サイト構造変更時にメンテナンス必須 |
| こんな方におすすめ | 自社専用ツールを作りたい方、エンジニアリソースがある方 |
| 評価(☆5段階) | 直感的な操作性:★★☆☆☆ 対応できるサイトの幅広さ:★★★★★ データ精度・安定性:★★★★★ 保守・メンテナンス性:★★★☆☆ コストパフォーマンス:★★★★★ |
実際に使ってみた感想
最初はコードを書くことに抵抗がありましたが、思い通りにデータを取れる自由度の高さは圧倒的。
ただ、サイト構成が変わるたびに手直しが必要になるので、保守管理は必須です。
「スクレイピングを自社資産として活用したい」方には強力な武器になるでしょう!
サービスの概要・使い方・特徴を紹介
Pythonでスクレイピングコードを自作することで、目的に完全フィットしたデータ収集が可能になります。
主な特徴は以下の通りです。
・HTMLを解析し、欲しい情報だけ抽出
・サーバー負荷を避けた丁寧なクローリングも可能
・APIがないサイトにも対応可能
具体的な設定手順(5ステップ)
- Python開発環境(Anaconda+VSCode)を準備する
まずAnaconda(Pythonの統合環境)を公式サイト(https://www.anaconda.com )からインストールします。

- コードを書くにはVisual Studio Code(VSCode)がおすすめ。拡張機能「Python」も入れておきます。
- 必要なPythonライブラリをインストールする
VSCodeでターミナル(コマンドプロンプト)を開いて、以下を実行します。
pip install requests beautifulsoup4
- 取得したいWebサイトの構造を確認する
Chromeの「検証ツール」(右クリック→検証)を使って、欲しい情報がどのHTMLタグに入っているか調べます。
- Pythonでスクレイピング用コードを書く
例えば次のように書きます。
import requests
from bs4 import BeautifulSoup
# 任意の検索URL(東京都 賃貸 マンションの検索結果例)
url = 'https://suumo.jp/chintai/tokyo/sc_shinjuku/?page=1'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
# 物件情報ブロックを取得
listings = soup.find_all('div', class_='cassetteitem')
for item in listings:
try:
# 物件名
title = item.find('div', class_='cassetteitem_content-title').text.strip()
# 住所
address = item.find('li', class_='cassetteitem_detail-col1').text.strip()
# アクセス
access = item.find('li', class_='cassetteitem_detail-col2').text.strip()
# 築年数
age = item.find('li', class_='cassetteitem_detail-col3').text.strip()
# 家賃
rent = item.find('span', class_='cassetteitem_other-emphasis').text.strip()
print('物件名:', title)
print('住所:', address)
print('アクセス:', access)
print('築年数:', age)
print('家賃:', rent)
print('------------------------------')
except Exception as e:
print("パースエラー:", e)
欲しいデータを抽出して、リストやCSVに保存できるようにしていきます。
自社で自動化する際によくある失敗ランキング
 自動化ツールを導入すれば業務が自動化され、効率が劇的に向上する——。
そう考えている企業は多いですが、実際には多くの企業が自動化ツールを十分に活用できていません。
有名な自動化ツールであるRPAを例にあげても、導入した企業の実態は理想と大きく異なった結果となっています。
自動化ツールを導入すれば業務が自動化され、効率が劇的に向上する——。
そう考えている企業は多いですが、実際には多くの企業が自動化ツールを十分に活用できていません。
有名な自動化ツールであるRPAを例にあげても、導入した企業の実態は理想と大きく異なった結果となっています。
RPA導入企業の約60%が「あまり活用できていない」と回答
 多くの企業がRPAを導入しているにも関わらず、約60%の企業が「期待したほど活用できていない」と感じているというデータです。これは、「導入しただけでは、業務改善につながらない」という現実を示しています。
多くの企業がRPAを導入しているにも関わらず、約60%の企業が「期待したほど活用できていない」と感じているというデータです。これは、「導入しただけでは、業務改善につながらない」という現実を示しています。
RPAの効果を実感できない要因は『RPA開発が進んでいない』
 「RPAの効果を実感できていない」と回答した企業の多くが、その理由として「RPA開発が進んでいない」「他業務・他部署への展開ができていない」ことを挙げています。
「〇〇業務はツールを導入すればすぐにラクになるはず」と思って、自社で自動化に挑戦した方も多いのではないでしょうか?しかし私たちには、こんな“あるあるの失敗談”がよく届きます。
「RPAの効果を実感できていない」と回答した企業の多くが、その理由として「RPA開発が進んでいない」「他業務・他部署への展開ができていない」ことを挙げています。
「〇〇業務はツールを導入すればすぐにラクになるはず」と思って、自社で自動化に挑戦した方も多いのではないでしょうか?しかし私たちには、こんな“あるあるの失敗談”がよく届きます。
🥇 第1位:初期設定でつまずき、結局断念…
思っていたより設定が複雑で、ツールの仕様を理解する前に挫折してしまうケース。 特にRPAツールやノーコードツールは、「慣れるまでが大変」という声が多いです。🥈 第2位:担当者が辞めて、運用不能に…
担当者が社内で唯一のキーマンだった場合、その人がいなくなると全て止まってしまうという問題が発生します。 しかも、「誰も中身が分からないから触れない」という状況になりがち。🥉 第3位:不具合や修正対応に時間がかかる…
自動化が止まったとき、「誰が見ればいいのか分からない」「ベンダーに相談するのも手間」という理由で、対応が後手に。 気づけばその対応に何時間も時間を取られ、本業に集中できなくなってしまうことも…。 実はよくある…自社で自動化に挑戦したときの“落とし穴” 共通するのは「すべて自社で完結しようとした」こと。 このようなケースに共通するのが、「最初から最後まで、すべて自社で完結しようとした」点です。 最初はうまくいっても、長期的に安定した自動化運用には、継続的な保守や柔軟な調整が不可欠です。安定的に自動化したいならジドウカがおすすめ
 「ツールを入れただけ」では業務はラクになりません 「業務をラクにする自動化」のためには、設定・運用・トラブル対応まで含めてプロに任せるのが最も確実です。
「ツールを入れただけ」では業務はラクになりません 「業務をラクにする自動化」のためには、設定・運用・トラブル対応まで含めてプロに任せるのが最も確実です。
ジドウカとは?
業務の一部を“タスク単位”で自動化し、月額で安定運用できるサブスクリプション型のサービスです。 技術のことが分からなくても、「こういう作業をラクにしたい」と伝えるだけでOK。ジドウカでできること(業務例)
・定期レポートの自動作成とSlack送信 ・受注データのExcel整形とkintone登録 ・競合サイトの自動モニタリングとアラート通知 ・営業リストの自動生成とCRMへの投入 などジドウカが選ばれる理由
弊社の自動化サービス「ジドウカ」は、1社1社、1タスク1タスクに合わせて完全オーダーメイドで開発するサービス担っています。- ヒアリングから開発・運用まで丸ごとサポート
- トラブル発生時には即時対応
- 月額料金内で自由に修正をご依頼可能
まとめ
手作業による情報収集は時間がかかりミスも起こりやすく、リアルタイム性にも欠けます。こうした課題を解決するのがスクレイピングツールです。
本記事ではノーコードで初心者向けのOctoparse、高機能で動的ページにも対応できるParseHub、自由度が高くエンジニア向けのPython(Requests+BeautifulSoup)の3つを紹介しました。
目的やスキルに応じて最適なツールを選べば、効率的かつ正確にWeb情報を収集できます。