


30人分の仕事を少数でこなす組織を創りたい経営者・マネージャーへ
Dify / n8n / Zapier / make / GAS / ChatGPT / Gemini等
あなたの周りにも「なぜか社員数は同じくらいなのに、あそこの会社の方が生産性高い気がする…」と思う会社ありませんか?
まさか「うちの社員が手を抜いてるに違いない…!」とか思ってないですよね?
そんな会社になれる方法、そこには「ある条件」がありました。
再現性高く生産性の高い組織を創るためには共通化した「ある条件」、それは
「キャッチアップ(情報処理)のスピードが速い」
ということです。
今「社員の能力が違うじゃないか!」って思いましたか?
能力は正直問題ではありません。
問題なのは、「キャッチアップ時に、どんだけ頭を空っぽの状態にできるか?」という環境づくりです。
例えば、面倒な作業があり、それを自動化するために新しいツールの使い方をキャッチアップする必要があるとします。
自動化ツールは、誰でも「時間をかければ」できるようになります。
そう「時間をかければ」。
「時間をかければ自分たちだってキャッチアップできるはず」って思っていませんか?
よく考えてみてください。
あなたは、そんな時間を捻出させられますか?
そんな環境を用意できますか?
今ギクッとなった方、安心してください。
それはあなたのせいではありません。
現代が「情報過多すぎる」せいです。
・無造作に手に取ってしまうスマホ。
・鳴り止まない通知。
・脳内で「やらなきゃ」と思っている残タスク。
気づかぬ間に、あなたの脳内マインドシェアは他人の創作物に搾取されています。
脳内のマインドシェアが常に10%しかない状態でキャッチアップしようとしているのです。
これは、エベレストで90分間サッカーをしているのと同じです。
パフォーマンスが高いはずがありません。
十分なマインドシェアを用意さえできれば、あなたもあなたの社員も
自動化ツールを使いこなし、生産性は上がっていくはずです。
自動化ツールに限らず、大きな経営の意思決定も納得できるものになるはずです。
人間の脳が本気集中状態を持続できる時間はたったの「1.5分」。
単調な仕事だと「25分」でパフォーマンスが下がると言われています。
そもそも、こんな情報過多な時代に自分のチカラだけで何か新しいことをキャッチアップしようとするのは、戦場に竹槍で戦いに挑もうとするくらい無謀です。
だから、今あなたに必要なのは、「情報のキャッチアップのスピードを効率化する仕組み」です。
本当に使える、質の高い情報を、時間をかけて咀嚼し、理解する、仕組みです。
だから私たちは、頭を空っぽにして生産的な業務や整理された情報による意思決定ができるように、自動化ツールやノウハウを使って業務を簡易化できる支援を事業として行なっています。
でも、いきなり予算をかけるのは心配ですよね?
だから、そんなあなたのために、まずは有料級のノウハウを発信する公式ラインを開設しました🎉
網羅的に自動化ツールを扱い、実際に弊社で自動化した内容で、ツールの使い方をどこよりも細かく、スクリーンショット満載で載せています!
大事なことなのでもう一度いいます。
「自動化できるんだろうけど、キャッチアップしている時間がないから今は人力で対応、、、!」
と思っているあなた、残念ながらあなたは一生、誰かの創作物の奴隷です。
これを機に「思考の余白」を創りませんか?

私はもともとレガシー産業のDX推進を担当していました。
いろんな課題はありましたが、社内は一定のデジタル化をなんとかすすめていくことに成功しましたが、なにより根深い問題だったのは業界自体がデジタルとは程遠いため、社内だけのDX化ではなかなか根本的な改善にはレバレッジが効かなかったということです。
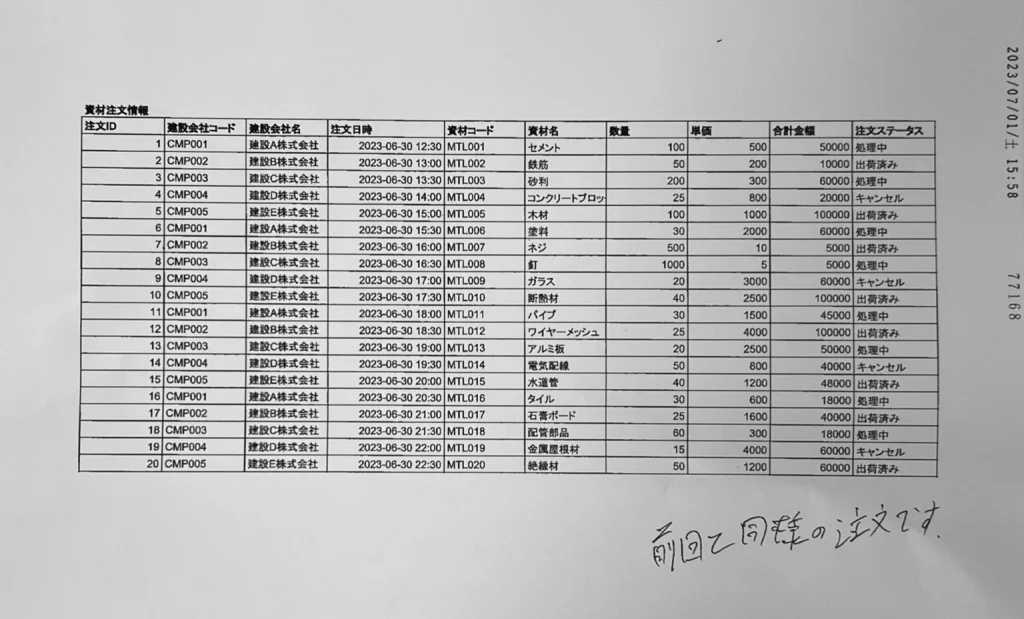
特に仕入れ先からの仕入先データや受注データを受け取る際は、エクセルをプリントアウトし、PDF化して、それをFAXで送られるという、なかなか巧妙なやり取りをしていました。
PDFでデータが送られてくるため、そのデータを受け取った事務員は一つ一つ手作業で入力するという多重コストがかかる運用をおこっていました。
今回の記事では、このような状態を半自動化することができる内容になります。 同じようなことで悩まれている経営者さんやDX担当者さんには目から鱗な内容になっておりますので、ぜひ最後までお読みください。
全体の処理工程
今回、2段階の処理工程を踏んで、FAX帳票データを半自動でCSV化する
(FAXを受け取る)
①OCRでFAXをだいたいの精度でCSV化する
②OCRでは精度が十分に出ないため、LLMに推論させてデータの精度を上げる
以下にそれぞれの細かい処理工程をまとめてみました。
OCR(FAX内容をOCRでCSV化する)
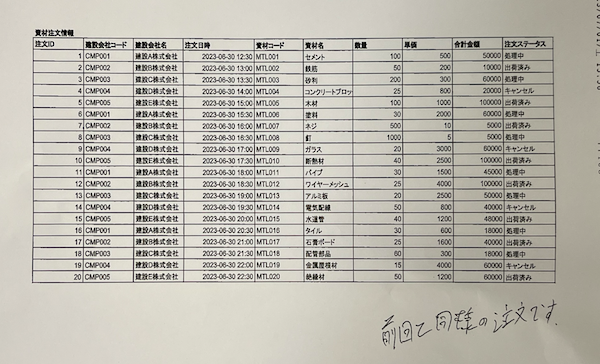
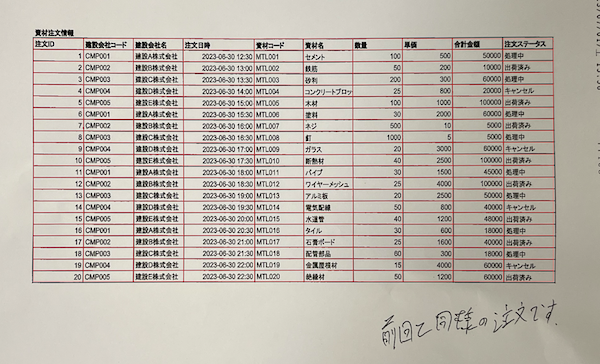
まずはこれを素材データとします。
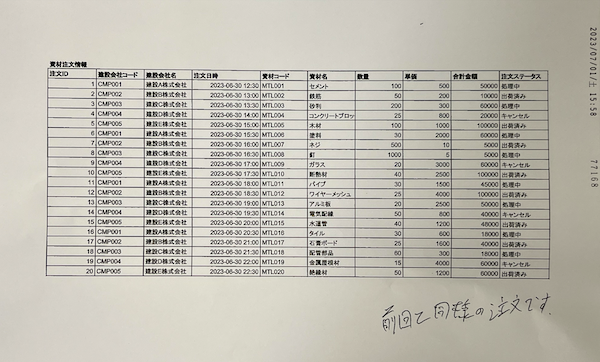
この画像データが最終的に精度高くCSV化されれば、成功です。それでは早速解説します。
OCR処理としては以下の3段階です。
①読み取りやすくする+読み取る範囲を設定する
②読み取る
③CSVとして出力する
それでは詳しく説明していきます。
①読み取りやすくする+読み取る範囲を設定する
画像を読み取りやすくするための下ごしらえ
①黒線をパキッとする(グレースケール変換)
まずは罫線の検出を簡単しやすくするために、グレースケールに変換します。もとの画像と比較すると線がパキッとしたことがわかります。
②枠線の抽出
つぎにセルの枠線+文字の枠線を取得します。

③枠線を視認しやすくする(膨張処理)
セルの枠線も、文字の枠線も太くなるように加工します。

④画像内での長方形の位置を調整します
この赤い長方形を、
黄色の線のサイズにもっていきたいので、、、
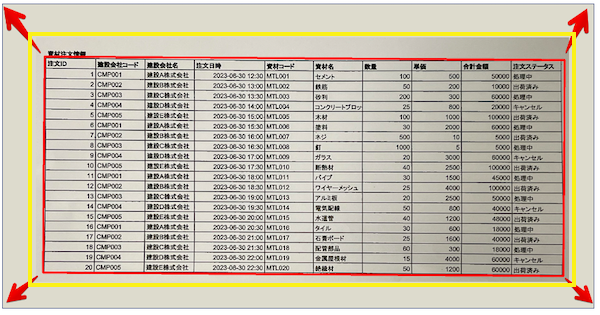
赤矢印の方向にひっぱると、、、
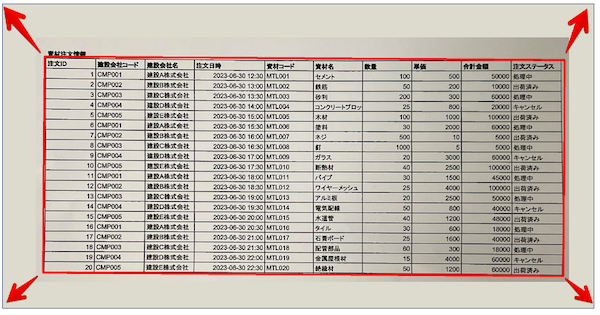
こうなって読み取りやすくなりました!
1セルごとのセルの枠線を読み取り、セルのだいたいの範囲を理解する
読み取りやすくなった画像を、今度は1セルごとの枠線を読み取らせます。
枠線だけを表示したらこんな感じになります。よーく見ると1セルごと枠線を識別しているので線が重なっているところがあったり、縦線・横線が曲がっている箇所があります。つまり誤差が乱発している状態になっています。

だいたいのセルの枠線から誤差を取り除く
今のままでは、セルの状態が以下の状態になっている。これでは座標として利用するのは難しいので、近似値を集約することで帳票の座標とします。
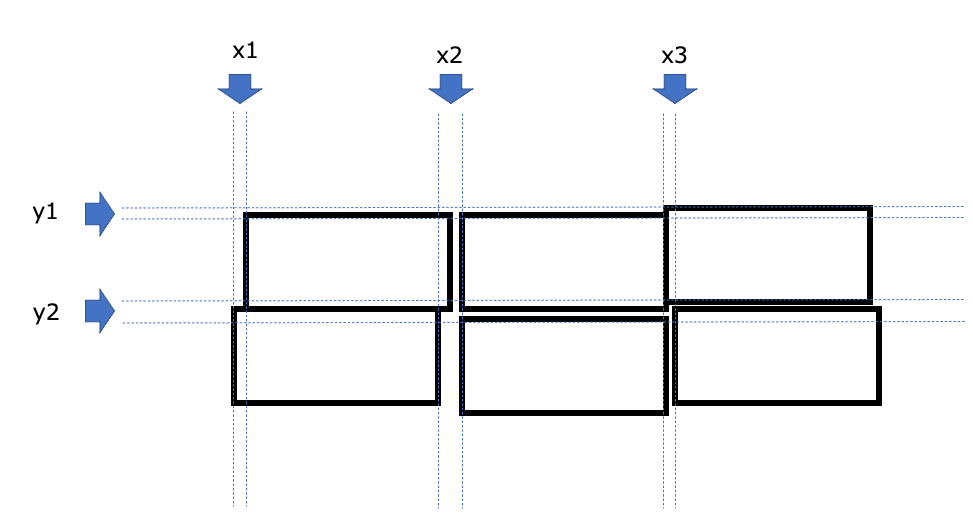
そうすると、ばらばらだった枠線が以下の赤線のように整います。
赤線だけを表示するとこんな感じになります。

これで「①読み取りやすくする+読み取る範囲を設定する」の準備完成!
②AI-OCRで読み取る(Microsoft Computer VisionのRead API)
日本語利用のAI-OCRでは、現時点でこのRead APIが精度が最も高いらしいのでRead APIを使用します。さきほどのこの画像をRead APIで読み取ります。
そうすると以下のような配列で出力されます。
{
"status": "succeeded",
"createdDateTime": "2023-07-02T06:47:56Z",
"lastUpdatedDateTime": "2023-07-02T06:47:57Z",
"analyzeResult": {
"version": "3.2.0",
"modelVersion": "2022-04-30",
"readResults": [
{
"page": 1,
"angle": 0,
"width": 2009,
"height": 1218,
"unit": "pixel",
"lines": [
{
"boundingBox": [
113,
96,
246,
97,
246,
122,
113,
121
],
"text": "資材注文情報",
"appearance": {
"style": {
"name": "other",
"confidence": 0.972
}
},
"words": [
{
"boundingBox": [
119,
96,
134,
97,
133,
122,
118,
122
],
"text": "資",
"confidence": 0.989
},
{
"boundingBox": [
142,
97,
157,
97,
157,
122,
141,
122
],
"text": "材",
"confidence": 0.965
},
・・・略・・・
③CSVとして出力する
上記のフローを経て、いよいよCSVデータとして出力します。
ReadAPIの応答データには、テキストが見つかった場所を示すboundingBox情報が含まれています。この情報を使用して、既に識別されているフォームの座標とマッチングさせることで、どのセルに特定のテキストが属するかを判断できます。
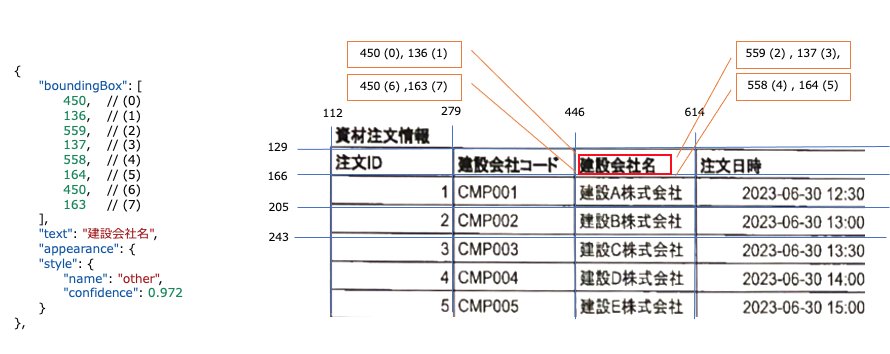
このようなCSV化に成功します。
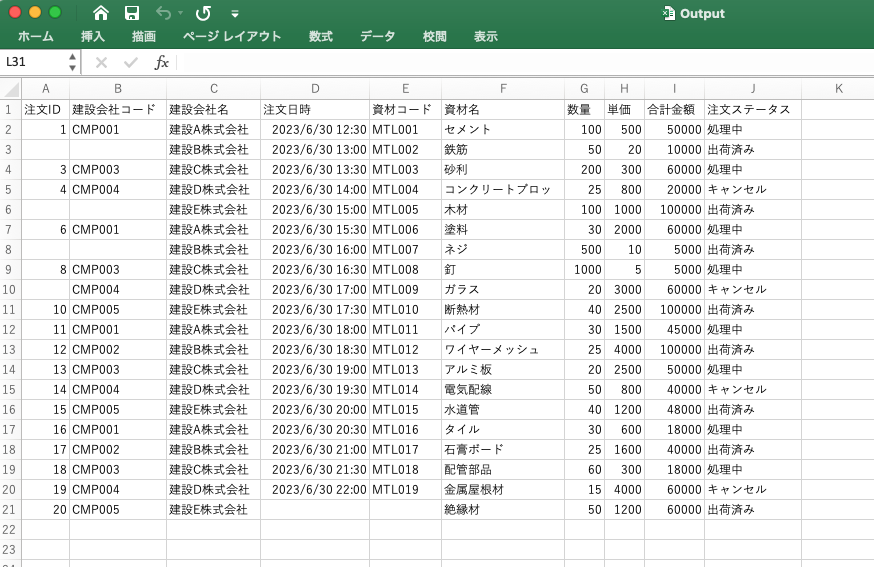
しかし、まだ問題があります。そこでLLMの登場です。
LLM(推論させてデータの精度を上げる)
OCRで出力されたCSVの課題点
OCRで出力されるデータの問題点を整理すると大きく2つの課題があります
課題①:OCRで読み取れず、空白のセルがところどころある
課題②:OCR読み取り時に、セルに入りきらず途中できれている文字列がそのままになっている
この2つをLLMで解決します。
まずは課題①から着手していきます。
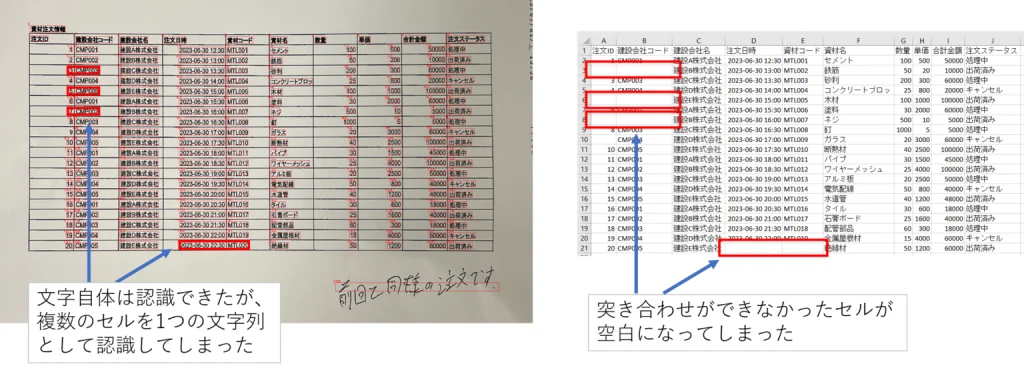
空欄セル内のテキストデータをどこで分割させるべきなのか、前後のセル情報をLLMに渡し、推論させる
空欄セルの位置を特定する + 空欄セル内のテキストデータをOCRで取得する
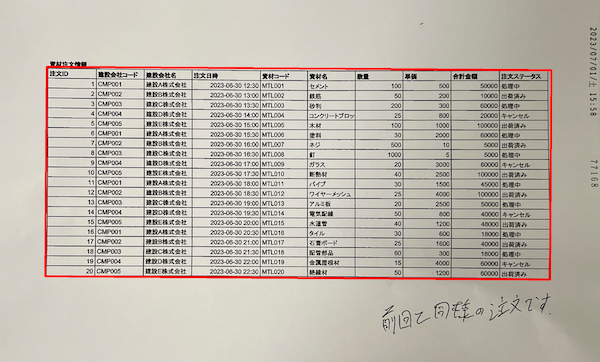
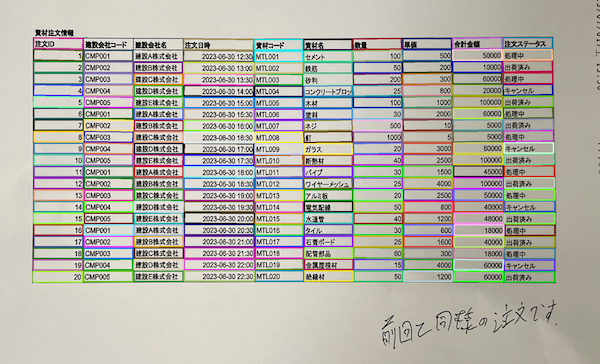
下の画像内の青枠線が空欄セルの箇所になります。空欄セル内のテキストデータを取得します。
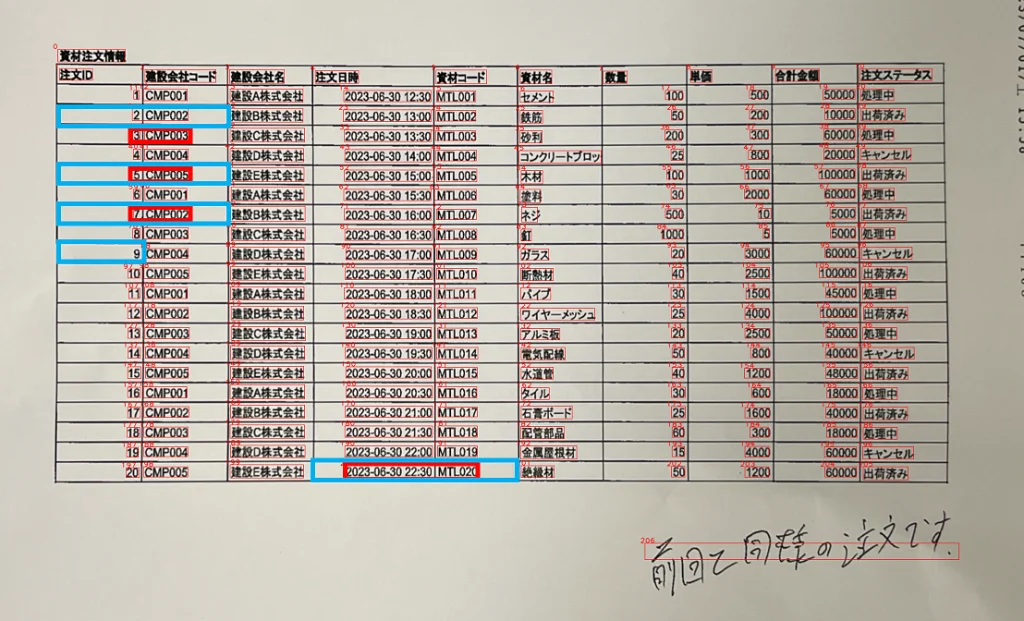
次に空欄セルの前後の情報を取得します。
空欄セルのテキストデータと、空欄の前後の情報をLLMに取り込み、推論させます。
prompt_template = """
OCRで複数のセルの文字列を読み込んだのですが、誤って1つのセルとして読み込んでしまいました。前後の行のように"{splitter}"で分割してください。分割した結果のみ出力してください。
# 前後の行
{near_rows}
# 分割したい文字列
{target_row}
# 分割結果
"""prompt = prompt_template.format(
splitter=SPLITTER,
near_rows="\n".join([SPLITTER.join(line) for line in near_cells_list]),
target_row=ocr_text,
)
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=OPENAI_MODEL,
temperature=0.0,
messages=messages,
)
content: str = response["choices"][0]["message"]["content"]以下が実行の例
OCRで複数のセルの文字列を読み込んだのですが、誤って1つのセルとして読み込んでしまいました。前後の行のように","で分割してください。分割した結果のみ出力してください。
# 前後の行
1,CMP001
3,CMP003
4,CMP004
# 分割したい文字列
2 CMP002
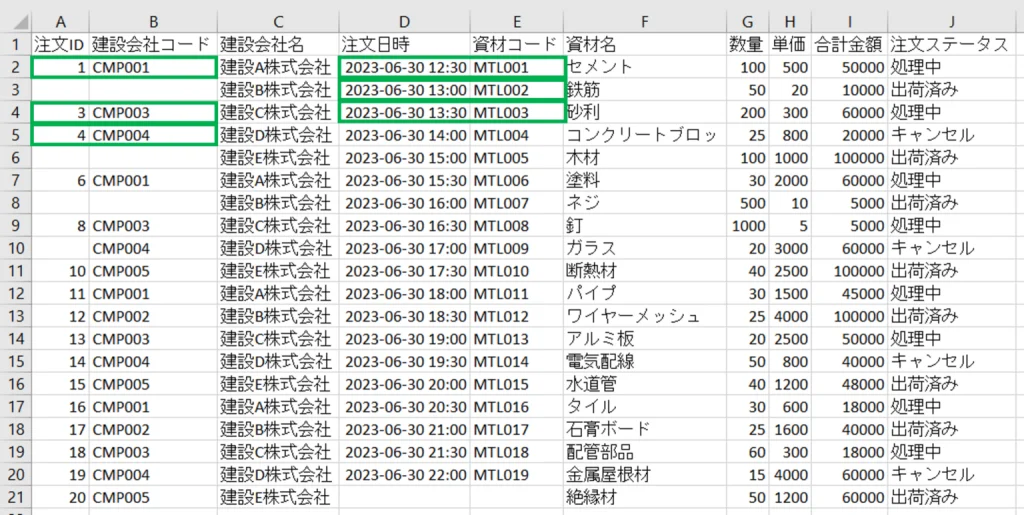
# 分割結果結果
正しく分割され、CSVが更新されました。
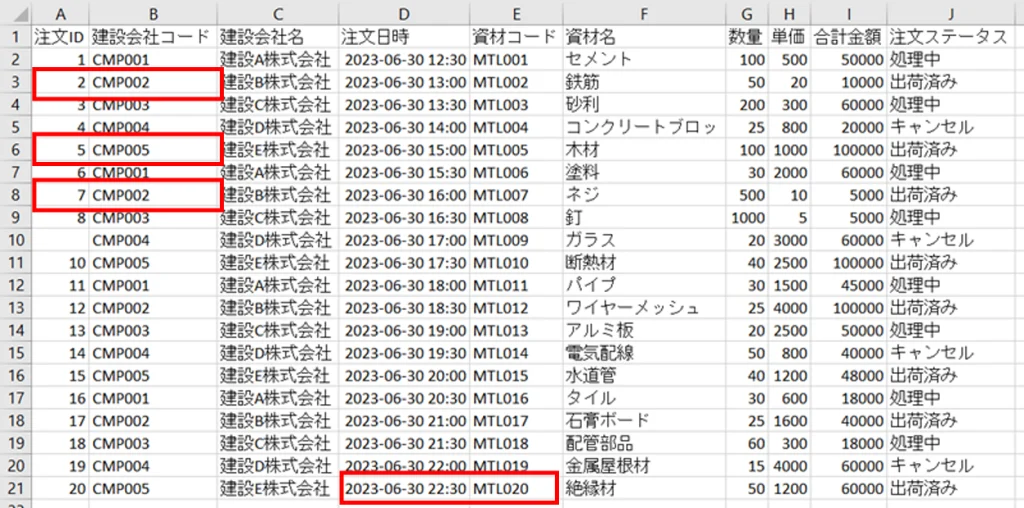
次に課題②に着手します。
OCR読み取り時に、セルに入りきらず途中できれている文字列がそのままになっている
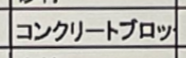
上記のようにセルに全文入り切らない文字列は「コンクリートブロッ」という意図しない文字列としてOCRで読み取りがされてしまいます。
そのため、以下のようなプロンプトによってLLMに推論させることが可能でした。
最後に
いかがだったでしょうか?
弊社では
明確に「生成AIで〇〇をしたい!」は無いけど、何か生成AIを使って取り組みたい!
というご要望にお応えしております。
これまでお取引させていただいた企業様も、ご相談時にはやりたいことが決まっていなかったことが多くあります。
ご相談を受け、一緒に考えさせていただく中で、生成AIとどこが相性が良いのか、それを構築するためにはどのようなデータが必要なのかを「無料お問い合わせ」にてお受けしております。
まずは、「無料相談」にてご相談を承っておりますので、お気軽にご連絡ください。