


30人分の仕事を少数でこなす組織を創りたい経営者・マネージャーへ
Dify / n8n / Zapier / make / GAS / ChatGPT / Gemini等
あなたの周りにも「なぜか社員数は同じくらいなのに、あそこの会社の方が生産性高い気がする…」と思う会社ありませんか?
まさか「うちの社員が手を抜いてるに違いない…!」とか思ってないですよね?
そんな会社になれる方法、そこには「ある条件」がありました。
再現性高く生産性の高い組織を創るためには共通化した「ある条件」、それは
「キャッチアップ(情報処理)のスピードが速い」
ということです。
今「社員の能力が違うじゃないか!」って思いましたか?
能力は正直問題ではありません。
問題なのは、「キャッチアップ時に、どんだけ頭を空っぽの状態にできるか?」という環境づくりです。
例えば、面倒な作業があり、それを自動化するために新しいツールの使い方をキャッチアップする必要があるとします。
自動化ツールは、誰でも「時間をかければ」できるようになります。
そう「時間をかければ」。
「時間をかければ自分たちだってキャッチアップできるはず」って思っていませんか?
よく考えてみてください。
あなたは、そんな時間を捻出させられますか?
そんな環境を用意できますか?
今ギクッとなった方、安心してください。
それはあなたのせいではありません。
現代が「情報過多すぎる」せいです。
・無造作に手に取ってしまうスマホ。
・鳴り止まない通知。
・脳内で「やらなきゃ」と思っている残タスク。
気づかぬ間に、あなたの脳内マインドシェアは他人の創作物に搾取されています。
脳内のマインドシェアが常に10%しかない状態でキャッチアップしようとしているのです。
これは、エベレストで90分間サッカーをしているのと同じです。
パフォーマンスが高いはずがありません。
十分なマインドシェアを用意さえできれば、あなたもあなたの社員も
自動化ツールを使いこなし、生産性は上がっていくはずです。
自動化ツールに限らず、大きな経営の意思決定も納得できるものになるはずです。
人間の脳が本気集中状態を持続できる時間はたったの「1.5分」。
単調な仕事だと「25分」でパフォーマンスが下がると言われています。
そもそも、こんな情報過多な時代に自分のチカラだけで何か新しいことをキャッチアップしようとするのは、戦場に竹槍で戦いに挑もうとするくらい無謀です。
だから、今あなたに必要なのは、「情報のキャッチアップのスピードを効率化する仕組み」です。
本当に使える、質の高い情報を、時間をかけて咀嚼し、理解する、仕組みです。
だから私たちは、頭を空っぽにして生産的な業務や整理された情報による意思決定ができるように、自動化ツールやノウハウを使って業務を簡易化できる支援を事業として行なっています。
でも、いきなり予算をかけるのは心配ですよね?
だから、そんなあなたのために、まずは有料級のノウハウを発信する公式ラインを開設しました🎉
網羅的に自動化ツールを扱い、実際に弊社で自動化した内容で、ツールの使い方をどこよりも細かく、スクリーンショット満載で載せています!
大事なことなのでもう一度いいます。
「自動化できるんだろうけど、キャッチアップしている時間がないから今は人力で対応、、、!」
と思っているあなた、残念ながらあなたは一生、誰かの創作物の奴隷です。
これを機に「思考の余白」を創りませんか?

生成AIがビジネスや日常生活において革新的な変化をもたらしている今日、その中心にあるのがEmbeddingです。しかし、この重要な技術について解説された記事は、しばしば技術的な専門知識を必要とします。本稿では、非エンジニアでも決裁権を持つマネージャーが理解できるよう、Embedding技術とその応用についてわかりやすく説明します。
Embedding
はじめに、生成AIとは?
生成AIは、テキスト、画像、音声などのデータから新しいコンテンツを生成する技術です。最近ではChatGPTの誕生により生成AIが脚光を浴びるシーンが多くなりました。生成AIが出力する精度を高める技術としてEmbedding、つまりデータを数値化し、機械が理解できる形式に変換するプロセスがあります。
Embeddingとは?
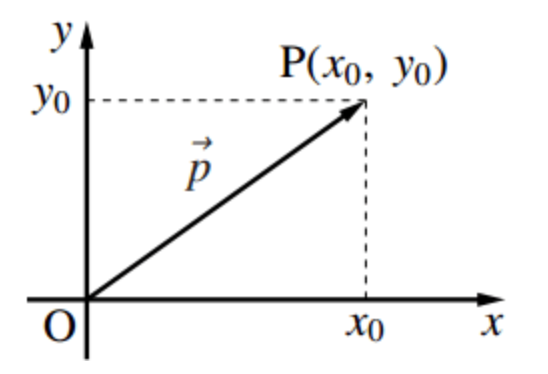
Embeddingとは「データをベクトル化する処理」という解釈ができます。簡単に言うと「人間の言葉を数字に変換する処理」と言った具合でしょうか。例えば、下図のように「犬」という人間語や「猫」という人間語がコンピュータが処理しやすいように数字の配列データになるようなイメージです。

上の図のように、テキストをベクトル形式に変換する方法が広く普及しています。特に、Embeddingモデルの進化により、この変換作業を誰でも容易に実施できるようになりました。たとえば、OpenAIが開発した「text-embedding-ada-002」という特定のモデルを使用することで、あらゆるテキストを1536次元のベクトルに変換可能です。このプロセスを利用する際に留意すべき重要な点を三つ挙げます。
- この変換手法では、テキストの長さに関係なく、使用するモデルによって一定の次元数のベクトルが生成されます。すなわち、「text-embedding-ada-002」を使用する場合、出力されるベクトルは常に1536次元になります。
- 異なるモデルを用いると、ベクトル化の際の次元数や数値の算出法が変わります。そのため、ベクトル間での比較を行う際は、同一のモデルを用いることが必須です。
- また、同一モデルを使用して同じテキストをベクトル化した場合、生成されるベクトルは毎回同じ結果となります。これにより、ベクトルを比較する際の一貫性が保証され、安心して利用することができます。
このように、テキストをベクトルに変換する技術は、一貫性と再現性を持ち合わせ、幅広い応用が可能です。
Embeddingの意味はわかったが、なぜEmbeddingする必要があるのか?
例えば、エクセルやワードで検索をかけたい場合は、特定の単語で検索をかけていると思います。その場合、完全一致しか検索をかけることができません。
生成AIの場合、Embedding化すればそれぞれのテキストの近似性を定量化し「似てるかも?」レベルのものを選択することができるのです。つまり完全一致ではなかったとしても近似しているものを検索することが可能なのです。
そのために、Embeddingは行われます。
Embeddingのメリット
・検索ワードと文章内のワードが完全一致していなくても類似性を調べられる
ベクトルとは
ベクトルは、方向と大きさを持つ量を表すために用いられる数学的な概念です。Embeddingにおいては、データを表すために多次元のベクトルが使用され、これにより複雑なデータ構造を簡潔に表現できます。
より詳しく知りたい人向け!類似度を計測するコサイン類似度とは?
ベクトル化されたデータの類似性を測定する方法の一つがコサイン類似度です。これは、二つのベクトル間の角度のコサインを計算することにより、類似性を数値化します。
コサイン類似度とは?
-1.0に近づけば近づくほど、類似していない。
1.0に近づけば近づくほど、類似している。
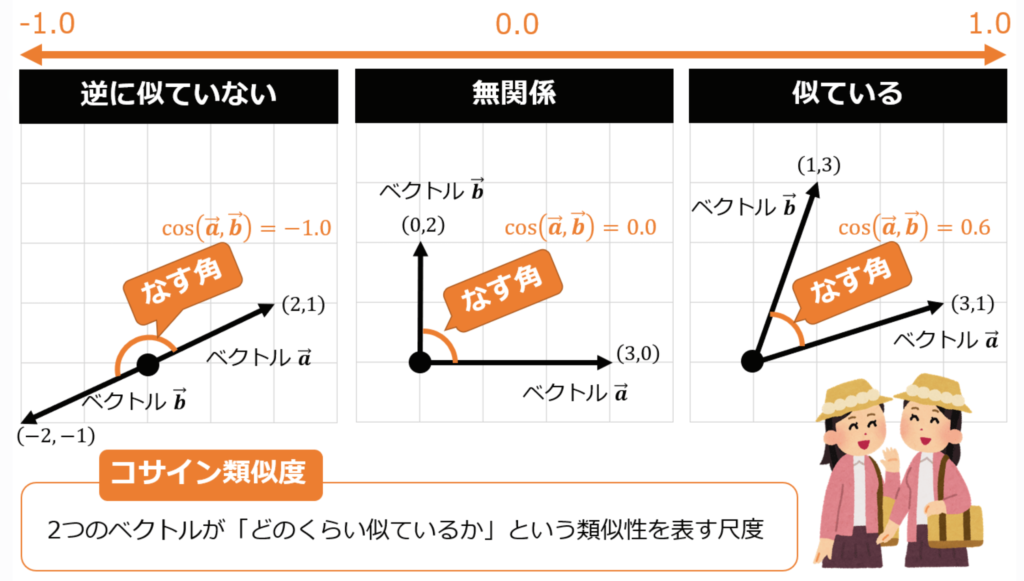

基本的に、「ベクトル間の内積とベクトルの大きさの積の比」により、cosθを求めることができます。この計算は、ベクトル化によって得られる数値の配列があれば実行可能です。このプロセスに深い関心がない方も、簡単に計算できることだと認識していただければと思います。
「焼き肉は美味しい」と「焼き肉は美味しくない」は似た意味だと判断?
Embeddingで精度の参考になるブログがあったので紹介させていただきます。
「焼き肉は美味しい」「焼き肉は美味しくない」「刺し身は美味しい」「刺し身は美味しくない」「ジュゲムジュゲム」の5つのテキストをそれぞれEmbeddingして、類似度を計測した結果が以下の通りになったそうです。
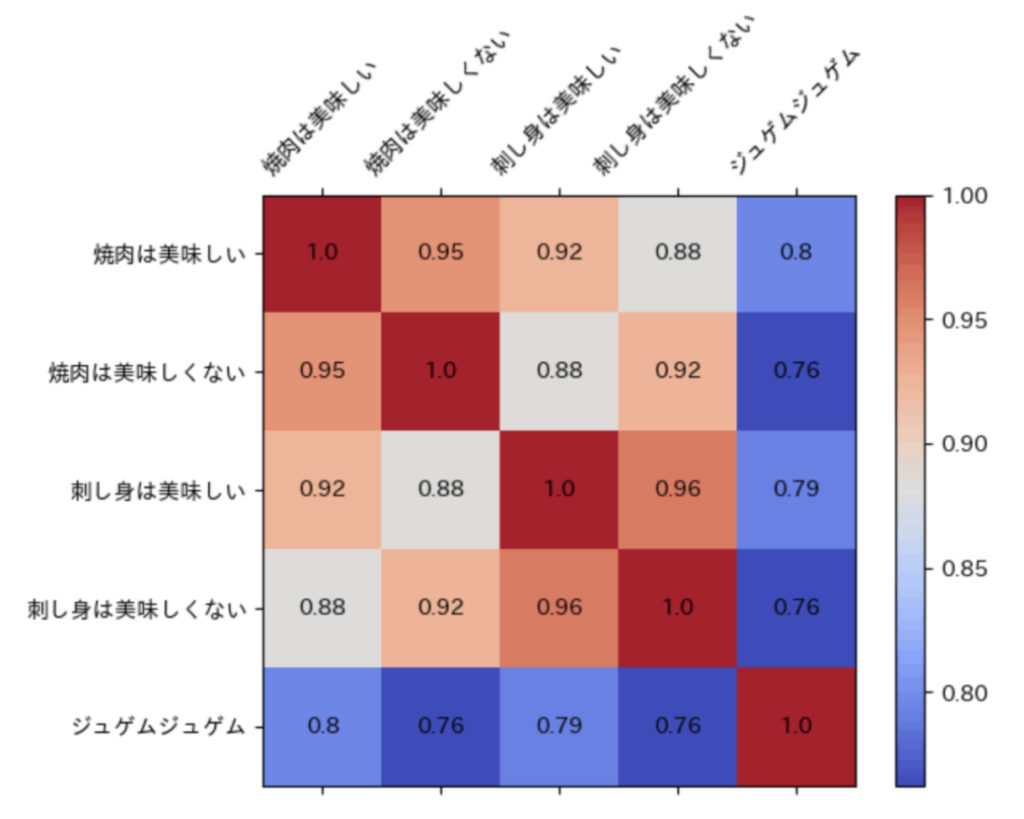
左上の「焼き肉は美味しい」と「焼き肉は美味しい」という2つのテキストを比べたとき、その類似度は1(つまりかなり近似している)と判断されました。
一方で「焼き肉は美味しい」と「焼き肉は美味しくない」という2つのテキストを比べたときも0.95と同じ位の類似度を算出しました。この段階だとEmbeddingでは「焼き肉は美味しい」と「焼き肉は美味しくない」は同じ意味合いだと評価されたようです。
執筆者いわく、「コサイン類似度が近い => 近いジャンルのテキスト」くらいの理解でいるのが安牌そうです。
この例のような事象だけに目を向けると、ベクトルを比較することで意味的な差異を把握することが難しいと感じるかもしれません。しかし、RAGのようなベクトル検索技術が示すように、類似した情報を識別する手段として、これらの比較は一定の効果を持っていると考えられています。技術が進化するにつれて、このようなモデルの精度はさらに向上すると期待されます。
最後に
いかがだったでしょうか?
弊社では
明確に「生成AIで〇〇をしたい!」は無いけど、何か生成AIを使って取り組みたい!
というご要望にお応えしております。
これまでお取引させていただいた企業様も、ご相談時にはやりたいことが決まっていなかったことが多くあります。
ご相談を受け、一緒に考えさせていただく中で、生成AIとどこが相性が良いのか、それを構築するためにはどのようなデータが必要なのかを「無料お問い合わせ」にてお受けしております。
まずは、ページ右上の「無料お問い合わせ」にてご相談を承っておりますので、お気軽にご連絡ください。